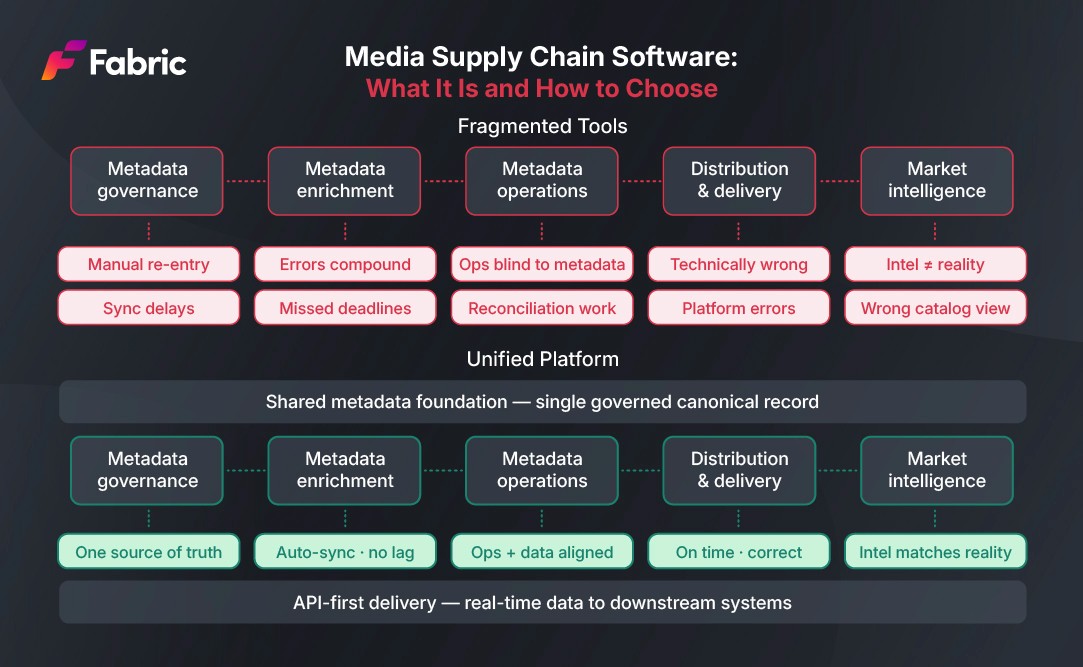
Pick any title in your catalog. Now ask three different departments what they know about it.
Your distribution team has one record, built for their delivery workflow, maintained in their system, updated when they need to update it. Your marketing team has another, built around campaign assets and promotional copy, living in a different tool entirely. Your rights management team has a third, focused on windows and territory clearances. None of these records is wrong, exactly. But they are not the same record. They were created independently, maintained independently, and have been diverging quietly ever since.
This is the metadata source of truth problem, and it is more common than most organizations want to admit. It is not a failure of diligence or a sign of poor management. It is the natural consequence of building operational workflows on top of systems that were never designed to share a single authoritative record, and of adding new platforms, partners, and distribution channels without revisiting the data architecture underneath.
The costs are real, even when they are hard to see.
What conflicting metadata actually costs
The most visible cost is the one that causes an incident: a title goes live on a platform with the wrong synopsis, or the wrong rating, or artwork that belongs to a different version. Someone notices. It gets escalated. It gets fixed. The post-mortem concludes that the wrong record was used, and the team resolves to be more careful.
The less visible cost is the permanent overhead of a fragmented metadata management environment. Someone is always the unofficial arbiter of which record is correct, the person other people call when two systems disagree. Reconciliation work happens before every major delivery, taking time that should be spent on higher-value tasks. New platform integrations take longer than they should because each one requires a new mapping from the local data model to the partner's requirements. And every new system added to the stack makes the problem slightly worse, because it creates another potential source of divergence.
Over time, this overhead becomes structurally embedded. Teams build workarounds. Processes evolve around the limitations of the infrastructure rather than being designed for the work they are actually doing. The cost is real and recurring, but because it is distributed across dozens of small inefficiencies rather than concentrated in a single line item, it rarely gets the attention it deserves.
What a genuine source of truth requires
The phrase "single source of truth" gets used frequently in technology discussions, often to describe something that falls considerably short of the concept. A shared spreadsheet is not a source of truth. A CMS that other teams are supposed to reference but don't always is not a source of truth. A database that is manually synced to other systems on an irregular schedule is not a source of truth.
A genuine metadata source of truth has four properties that distinguish it from these approximations.
It is authoritative by design. The system is structured so that the canonical record lives in one place, and all other representations of that record are derived from it rather than maintained independently. When the canonical record changes, downstream representations update automatically rather than requiring manual propagation. This is what media records management looks like when it is built correctly.
It is governed. There are defined processes for who can create, modify, and approve records, and those processes are enforced by the system rather than by convention. Changes are tracked, versioned, and auditable. The question "what changed, when, and who approved it" always has an answer. This kind of title and episode metadata management at scale requires workflow governance that spreadsheets and shared drives simply cannot provide.
It is integrated. The source of truth feeds all downstream systems via API or automated delivery, rather than requiring manual export and re-entry at each integration point. The goal is that a change made once in the canonical system propagates correctly to every system that depends on it, without human intervention. An API-first records metadata management approach is what makes this possible in practice.
It is enriched. The canonical record is not just a container for manually entered data but is continuously augmented from authoritative external sources: normalized metadata, licensed imagery, contributor data, and availability information. Automated metadata enrichment is what keeps the source of truth current, not someone remembering to update it. This is the layer where content metadata enrichment and catalog metadata solutions do their most important work.
Organizations that have all four of these properties in place find that the operational overhead associated with metadata management for studios drops significantly, and that the quality and consistency of content data across their entire media supply chain improves as a direct consequence.
The integration layer that makes it work
One of the more underappreciated aspects of building a metadata source of truth is the integration architecture that connects it to the rest of the organization's systems. A canonical record that lives in one platform but has to be manually exported and reformatted before it can be used by any other system is not really a source of truth in practice. It is just a better-organized starting point for manual work.
The organizations that solve this problem effectively build on an API-first foundation: the canonical metadata management platform exposes its records via structured APIs that downstream systems consume directly, with the transformation logic managed centrally rather than duplicated across every integration. When the data model needs to change, the change is made once in the API layer, and all downstream consumers receive the updated structure automatically.
This architecture is more resilient than point-to-point integrations between individual systems, more scalable as new platforms and partners are added, and far more maintainable over time. It also makes the metadata source of truth genuinely trustworthy, because downstream teams know that the data they are consuming is current and governed, not a snapshot that may have diverged since the last manual sync. A unified data platform approach at the platform level is what enables this kind of trusted, always-current data flow across the organization.
Where Fabric sits in this picture
Fabric is built around the principle that metadata should be managed once and activated everywhere, across content discovery, distribution, rights management, market intelligence, and operations, from a single, governed, continuously enriched foundation.
The Origin product family provides the metadata integration infrastructure for the content layer. Origin Studio governs title and episode records as the metadata source of truth. Origin Nexus enriches those records with normalized metadata, licensed imagery, and content discovery data. And Origin Insights transforms the governed, enriched metadata into entertainment market intelligence that informs strategic decisions around acquisition, licensing, and audience demand trends.
The Xytech product family connects that metadata foundation to the operational layer. Resource and production scheduling in Xytech Operations, media workflow automation in Xytech Media, and delivery coordination in Xytech Transmission all draw from the same trusted data source, so that the data used to manage content and the data used to operate on it never diverge.
For media organizations evaluating how to consolidate fragmented metadata environments, Fabric's unified data platform represents an approach where the source of truth is not a single database sitting in isolation, but a coherent media data solutions architecture that flows from governance through enrichment through activation, across every part of the content business that depends on accurate metadata.
Join the conversation
The metadata source of truth problem is one of the most consequential — and most underinvested — infrastructure decisions in media. Follow Fabric on LinkedIn to stay connected with the thinking shaping how the industry is solving it.
Fabric is a global media data company. The Origin product family — Origin Nexus, Origin Studio, and Origin Insights — powers metadata enrichment, governance, and market intelligence for entertainment companies worldwide.
FAQ
Read More Articles
We're constantly pushing the boundaries of what's possible and seeking new ways to improve our services. Search your topic of interest.