
There is a version of the metadata problem that appears to be solved once a media organization adopts a modern, API-first platform and moves away from manual exports and point-to-point integrations. And then, gradually, new problems emerge.
Being API-first is a necessary foundation, but is it enough? The architectural decisions that determine whether a metadata management platform actually scales at enterprise level operate above the API layer, and they require deliberate design rather than emerging automatically from a platform choice.
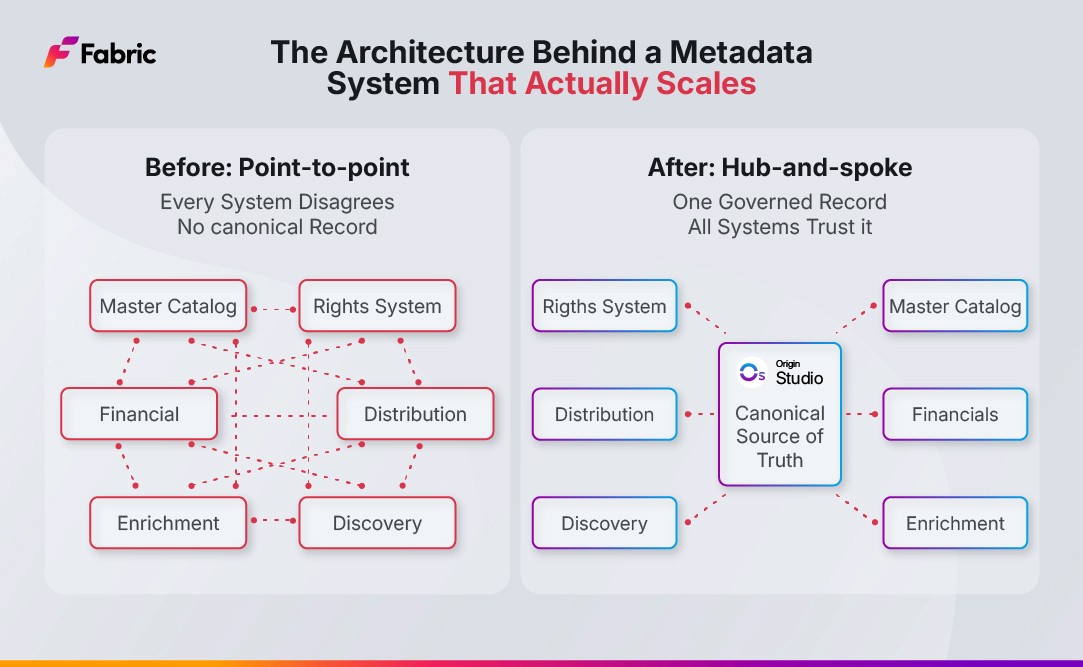
The canonical record problem
The most consequential architectural decision in any metadata system is the one that gets asked last: which system is authoritative for the canonical content record, and how is that authority enforced?
In most media organizations, this question has no clean answer. The master catalog lives in one system, the distribution records in another, the rights data in a third. Each was built to solve a specific problem, each is maintained by a different team, and each has become authoritative in its own domain through accumulation rather than design. The result is a metadata management environment where no single record can be fully trusted without cross-referencing it against the others.
An API-first delivery mechanism does not resolve this. If three systems each believe they hold the authoritative version of a title record, making them all API-first simply means they propagate their disagreements in real time to downstream systems more efficiently. The canonical record problem is not a delivery problem. It is a governance and architecture problem that needs to be solved at the data model level before the delivery mechanism becomes relevant.
The architectural answer is a hub-and-spoke model: a single platform designated as the metadata source of truth for content metadata, with all downstream systems reconfigured to consume from it rather than maintain their own independent copies. This requires organizational decisions as much as technical ones. Someone has to own the canonical record. Someone has to define what goes in it and what the standards are. Someone has to govern who can change it and how. The platform provides the infrastructure for those decisions; it cannot make them.
Why integration debt accumulates regardless of delivery mechanism
One of the more persistent misconceptions about API-first records metadata management is that it solves the point-to-point integration problem. It reduces it, but does not eliminate it, and understanding the distinction matters for anyone designing a metadata integration strategy at scale.
In a batch export model, each integration requires a bespoke connector: a scheduled process that pulls data from the source, transforms it into the format the downstream system expects, and pushes it to the destination. Each connector is a maintenance burden: it needs to be updated when the source data model changes, when the destination's ingestion requirements change, and when the sync schedule needs to be adjusted.
In an API-first model, each integration still requires mapping the canonical data model to the downstream system's requirements, and each downstream system still needs to be updated when the canonical model changes in ways that are not backward-compatible. What changes is the location and nature of the maintenance work. Instead of maintaining a bespoke connector for each integration, the downstream system maintains a client that consumes the canonical API. Backward-compatible updates to the API propagate automatically; genuinely new data points require downstream code changes. The work is consolidated rather than eliminated.
The architectural decision that most significantly reduces integration debt over time is not adopting API-first delivery but organizing the metadata integration model around a single canonical API rather than allowing it to grow into a mesh of bilateral connections. Each downstream system that consumes directly from the canonical API rather than from an intermediate system or a transformed copy of the data reduces the number of places where inconsistency can enter the chain.
Enrichment as architecture, not process
Metadata enrichment is typically treated as a process: a project to bring records up to a standard, completed once and then maintained through periodic updates. This framing consistently produces suboptimal outcomes because it treats enrichment as something that happens to a record after it is created rather than as a property of the architecture that creates it.
A metadata management platform designed for scale integrates enrichment at the point of record creation. When a new title enters the catalog, the record is created with normalized metadata, contributor data, licensed imagery, and availability information already populated from authoritative sources, rather than created bare and enriched later. This is not a subtle distinction. A bare record that enters a catalog and waits for enrichment creates downstream problems immediately: discovery systems cannot surface it correctly, distribution pipelines cannot deliver it completely, and the enrichment backlog grows faster than it can be cleared.
The architectural requirement is a platform that connects to authoritative enrichment sources at the point of ingestion, validates incoming data against a quality schema before it enters the canonical record, and maintains clear separation between what is governed internally and what is sourced externally. Origin Nexus provides the automated metadata enrichment layer that Origin Studio draws from at record creation, ensuring that records enter the governed catalog already carrying the normalized metadata that downstream systems depend on.
Governance as infrastructure
The final architectural layer that determines whether a metadata system holds up at scale is governance: the combination of data model design, access controls, approval workflows, and audit trails that determines who can change the canonical record, under what conditions, and with what oversight.
Governance is frequently treated as a policy layer sitting on top of the technical infrastructure rather than as part of the infrastructure itself. This leads to governance that is enforced through organizational convention rather than system design, which means it degrades as the organization grows, as teams change, and as the pressure to move quickly increases. In high-volume media catalog management environments, governance that depends on people remembering to follow a process will eventually fail.
The architectural alternative is a platform where governance is built into the data model: where metadata schemas define what fields are required and what values are valid, where role-based access controls prevent unauthorized changes at the system level rather than through policy, where stage-based approval workflows route records through the right review steps before they reach published state, and where every change is tracked and auditable without requiring a separate audit process. This is the governance infrastructure that makes themetadata source of truth trustworthy enough for all downstream systems to depend on it.
How Origin Studio is built for this
Origin Studio is designed around the full architectural stack described above, not just the API delivery layer. The platform establishes a single governed canonical record for every title in the catalog, with a hierarchical data model covering title and episode metadata across movies, series, seasons, episodes, and compilations that was built from day one to align with industry standards including EIDR.
Governance is built into the system rather than layered on top of it: configurable metadata models define what each record type requires, role-based permissions enforce who can create, edit, and approve records, and state flows route content from draft through publication with defined review steps at each stage. Every change is tracked and auditable. This is what studio metadata solutions look like when governance is treated as infrastructure rather than policy.
Content metadata enrichment is integrated at the point of record creation through Origin Nexus and other sources, which means records can enter the catalog carrying normalized metadata, licensed imagery, contributor data, and availability information sourced from authoritative external sources rather than waiting for manual population. The integration layer is API-first in the precise sense: downstream systems can consume from the canonical record in real time rather than maintaining local copies that drift from the authoritative source.
For organizations evaluating how to build a metadata scalability architecture that holds up at the scale and complexity of enterprise media distribution, the questions worth asking are above the API layer: what is the data model, how is the canonical record governed, where does enrichment happen, and how is the integration architecture organized. Origin Studio provides the infrastructure answers to those questions, and Origin Insights completes the picture by transforming the governed, enriched canonical record into the entertainment market intelligence that informs what goes into the catalog in the first place.
Get the latest from Fabric
We publish regular insights on metadata architecture, media records management, and the infrastructure decisions that determine how well media organizations scale. Follow Fabric on LinkedIn for new articles as soon as they drop.
Fabric is a global media data company. The Origin product family, including Origin Nexus, Origin Studio, and Origin Insights, powers metadata enrichment, governance, and market intelligence for entertainment companies worldwide.
FAQ
Read More Articles
We're constantly pushing the boundaries of what's possible and seeking new ways to improve our services. Search your topic of interest.






