In a market defined by infinite choice, content is no longer king — discoverability is. Yet media organizations continue to treat metadata as a static asset, a checkbox item to be completed upon ingestion and forgotten. This project mentality is the silent killer of catalog ROI. A record that technically exists is not the same as one that performs. If your metadata management isn't evolving in real time, you are actively obscuring your content from the audience it was meant for. To compete in the attention economy, we must stop viewing enrichment as a one-time task and start treating it as a dynamic, living business process.
Closing that gap is what content metadata enrichment does. The challenge is not understanding what enrichment adds. It is building the workflow that keeps it current as the catalog grows and the market changes around it. Metadata is never static. Understanding why is very important to enriching it as a process.
Understanding the Lifecycle of Metadata
Metadata is an organism. It has a lifecycle. It evolves over time. Its role changes too with the user's journey in relation to the title. Here are the four primary stages of a title's lifecycle.
Inception
Metadata starts with a title and an ID. Just like a country that assigns an ID to a person at birth, a title is assigned an ID at inception. A studio will use an internal ID and then will typically register it with EIDR to get an ID assigned. This is where the studio content registry begins its work, establishing the canonical identity of a title before any other data is attached to it. Contributors such as directors, producers, and cast will be added in this phase too.
Adolescence
Once an EIDR ID is assigned, it begins to build new relationships with other systems such as Fabric, Rotten Tomatoes, IMDb, TMDb, social media, and more. Prior to release, data begins to mature so studios will add a synopsis, a release date, title treatment art, and a trailer. This is the phase where content promotional data and video and imagery metadata begin to fill out the record.
As the release date moves closer, studios release more artwork in different aspect ratios, behind-the-scenes photos, featurettes, vertical videos for social media, duration, certification, and more cast and production lists. Creators will begin to create their own trailer breakdowns to help build anticipation. Celebrity metadata and contributor data become increasingly important at this stage as cultural momentum builds around key talent.
Maturity
Post release, new data will begin to flow from social media communities. They will provide ratings, reviews, and social media posts about the title. New actions such as purchasing tickets, buying, renting, or streaming, rating and reviewing, adding to watch queues, and marking as watched all generate audience demand trends that feed back into how the title is positioned and discovered.
Tracking of titles will also begin with daily box office revenue, award nominations, and trending lists. Analysis of success begins to be measured. Streaming market intelligence at this stage is what tells studios whether their title is performing where it was expected to and where gaps in distribution remain.
Second Life
Some older titles get a new life due to developing a cult following, award wins, a sequel release, editorial lists, addition to a new streaming platform, positioning on a platform, new syndication, or viral trends. For instance, the TV show The Office was only a moderate hit on NBC but became a streaming staple on Netflix. Another example is Donnie Darko (2001), which was a theatrical flop but found a cult following in its home video release. Understanding which titles in a catalog have this potential requires platform availability insights that show where demand is building relative to current distribution.
Mapping the User Journey
Metadata integration is the invisible connective tissue of the modern user experience. It transforms a static library into an intuitive, curated environment. Every interaction — browsing a homepage, selecting a title, or exploring behind-the-scenes content — is powered by the metadata you maintain. When that data is fragmented or outdated, the user experience fractures. To build a truly sticky platform, you must treat every user interaction as a data-creation event.
Consider the lifecycle of that interaction:
Before Watching (The Discovery Phase): Users engage with metadata to build intent. Trailers, spoiler-free reviews, cast lists, and thematic tags are not just details; they are conversion triggers. Content discovery data in this phase is the difference between a user scrolling past a title and adding it to their watchlist.
While Watching (The Immersion Phase): The experience extends beyond the asset itself. Metadata powers the contextual immersion — chapters, on-screen cast recognition, soundtrack information, and location data — that keeps a user engaged rather than distracted.
After Watching (The Retention Phase): The feedback loop starts here. Ratings, reviews, and social interactions provide the signals necessary to suggest the next title. This is where recommendation engines move beyond generic suggestions, leveraging real-time content insights like time of day, device, and history to surface the right content, at the right time, in the right context.
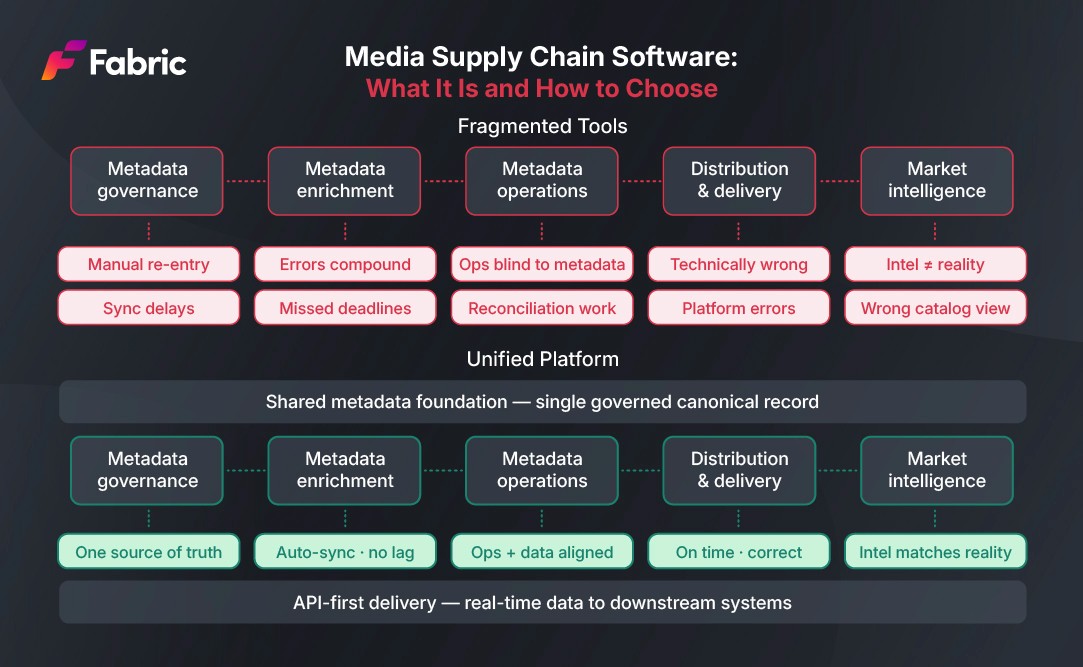
To ensure this journey remains cohesive, media companies require a centralized title and episode metadata management platform. Origin Studio serves as the metadata source of truth, providing the governance needed to maintain a clean, high-fidelity catalog. By leveraging Fabric's pre-integrated Origin Nexus, metadata enrichment workflows become automated, minimizing manual data entry and ensuring the record is production-ready the moment it enters your ecosystem. The result is a catalog that evolves at the speed of your users' demands, transforming metadata from a back-office burden into a front-end competitive advantage.
When licensing titles, it is easier to use a third party to assist with enrichment. Origin Studio is pre-integrated with Origin Nexus metadata. Clients can access millions of records from a simple search in Studio and the normalized metadata can fill in the record with title, synopsis, contributors, poster art, genres, themes, certifications, awards, localized data, and more, minimizing human data entry. If other sources need to be integrated, that data can be used to seed a catalog too.
The practical consequence is that the record is ready for downstream use immediately rather than sitting in a partially complete state waiting for enrichment work that may or may not arrive on a predictable schedule.
As a record's metadata moves through its lifecycle, the need for ongoing maintenance requires updates as circumstances change: availability windows open and close as distribution deals are made and expire, new awards are won, cast members become more or less prominent in the cultural conversation, and technical specifications change as new platform tiers are launched. Maintaining these updates manually across a large catalog is not feasible at the required velocity. The practical answer is automated metadata enrichment pipelines that monitor authoritative sources, identify changes relevant to records in the catalog, and update those records according to defined rules without requiring human intervention for routine changes.
Internally, media companies also need to manage quality governance. Metadata enrichment workflows that operate without validation introduce errors at scale. A normalized contributor record that links incorrectly to the wrong person propagates that error to every downstream system that consumes it. An availability data update that reflects a deal that was announced but not yet live creates incorrect information in distribution systems. Quality governance means validating incoming enrichment data against a quality schema before it is applied to the canonical record, flagging anomalies for human review, and maintaining an audit trail of what changed, when, and from which source.
Where most enrichment implementations fall short
The most common failure mode in content metadata enrichment is the legacy mindset of treating it as a project rather than a process. A catalog is enriched to a defined standard at a point in time, the project is considered complete, and ongoing maintenance is left to ad hoc updates as obvious gaps are noticed. The project mentality is the fastest way to kill a catalog's ROI.
The problem is that the catalog does not stand still. New titles arrive continuously. Existing titles gain new distribution windows, updated ratings, award recognition, and cast additions. Availability data changes as platform deals evolve. Imagery needs refreshing as licensed assets expire. A catalog that was fully enriched twelve months ago is measurably less complete today, and the rate of degradation is proportional to the volume and activity of the catalog. This is the metadata scalability challenge that automated metadata enrichment is built to address.
The second failure mode is inconsistent normalization. Enrichment data drawn from multiple sources uses different taxonomies, different entity representations, and different quality standards. A genre classification from one source does not map directly to the same genre classification in another. A contributor record from one provider may use a different name variant than the record in the catalog. Without a normalization layer that maps incoming enrichment data to a consistent internal standard, the enrichment process adds volume without adding coherence, and the catalog ends up with richer but less reliable data than it started with. This is where catalog metadata solutions with built-in normalization infrastructure make the most tangible operational difference.
The third failure mode is enrichment that cannot be delivered. A catalog with rich, normalized metadata that can only be delivered through periodic bulk exports is not actually providing the downstream systems that depend on it with accurate, current data. The API-first records metadata management delivery architecture matters as much as the enrichment itself.
How Origin Nexus delivers automated metadata enrichment
Origin Nexus is Fabric's metadata enrichment and content discovery platform, designed for media organizations that need depth, normalization, and currency across large content catalogs.
The platform delivers normalized metadata across movies and TV series at the point of record creation: titles, contributors, genres, releases, awards, and availability, sourced from authoritative external sources and validated before entering the catalog. Licensed imagery and promotional video are part of the same delivery layer, eliminating the complexity and licensing risk of sourcing assets separately. Availability data covers streaming platforms by territory with deep links.
At the discovery intelligence layer, Origin Nexus provides proprietary Power Ratings, themes, editorial and franchise collections, and audience affinity signals that go beyond standard attribute data. These are the enrichment signals that recommendation engines need to surface content intelligently rather than generically, and they represent the layer of the enrichment stack that commodity providers do not reach.
For organizations that also govern their own catalog records, Origin Nexus integrates directly with Origin Studio, so that enriched data flows from a single governed source into every downstream system. The delivery layer is API-first, designed for real-time consumption rather than scheduled bulk export, which means downstream systems always work from current enrichment data rather than from periodic snapshots.
n an era of endless content choices, the winner will not necessarily be the service with the most content, but the service with the most knowable content.
Thinking about media data strategy?
We publish regular insights on metadata enrichment, content discovery, and the infrastructure decisions that determine catalog quality at scale. Follow Fabric on LinkedIn for new articles as soon as they drop.
Fabric is a global media data company. The Origin product family, including Origin Nexus, Origin Studio, and Origin Insights, powers metadata enrichment, governance, and market intelligence for entertainment companies worldwide.
FAQ
Read More Articles
We're constantly pushing the boundaries of what's possible and seeking new ways to improve our services. Search your topic of interest.